
|
Kanaal 17
Een nieuwsrubriek
samengesteld uit berichten die
ons bereiken via de
reguliere en de gespecialiseerde
pers,
Internet, eigen
correspondenten en de lezers van dit
e-zine.
|
STEMACTEURS EN
PERFORMANCE CAPTURE-ARTIESTEN VOOR VIDEOGAMES STAKEN
 In
videogames is niet alles door de computer gemaakt - er
zijn ook échte mensen (buiten de ontwikkelaars
uiteraard) die meewerken; Zo bijvoorbeeld stemacteurs,
die de stemmen van de verschillende protagonisten
inspreken. En ook mensen die bewegingen voordoen, die
daarna door de computer omgezet worden naar een digitale
versie in de game - iets wat "performance capture"
artiesten genoemd wordt. In
videogames is niet alles door de computer gemaakt - er
zijn ook échte mensen (buiten de ontwikkelaars
uiteraard) die meewerken; Zo bijvoorbeeld stemacteurs,
die de stemmen van de verschillende protagonisten
inspreken. En ook mensen die bewegingen voordoen, die
daarna door de computer omgezet worden naar een digitale
versie in de game - iets wat "performance capture"
artiesten genoemd wordt.
Welnu, die laatstgenoemde groep en de stemartiesten
gingen verleden week in de VS in staking. De inzet:
hoeveel de motion capture prestaties betaald moeten
worden. De studio's beschouwen sommige fysieke
prestaties als "data", terwijl de vakbond SAG-AFTRA
meent dat dit beschouwd (en vergoed) moet worden als een
performantie.
De reden dat dit nu ter sprake komt, is dat er nu AI in
het spel is. Wanneer iemand een stunt doet, dan zou die
normaal gezien betaald worden per prestatie. Maar een
studio kan nu een model trainen op basis van die
prestatie, zodat de medewerking van die stuntman/vrouw
niet meer nodig is. En dat zonder dat deze persoon extra
compensatie krijgt.
De staking is enkel gericht tegen de grote
videogamestudio's. Voor de onafhankelijke studio's en
projecten die met een kleiner budget werken werd eerder
dit jaar al een aparte overeenkomst hierover getroffen.
Meer bij AP News en The Verge. Je ziet dat de komst van
AI op heel wat terreinen een impact heeft!
https://apnews.com/article/sagaftra-video-game-performers-ai-strike-4f4c7d846040c24553dbc2604e5b6034
https://www.theverge.com/2024/7/25/24206357/video-game-performer-strike-sag-aftra
OPENAI LANCEERT SEARCHGPT: BYE BYE G OOGLE? OOGLE?
 Het werd
algemeen verwacht, en verleden week was het zover:
ChatGPT heeft zijn eigen zoekmachine gelanceerd, die je
bereiken kan via chatgpt.com/search - tenminste, als je
tot een van de 10.000 testgebruikers behoort, die een
uitnodiging gekregen hebben. Was dat niet voor jou het
geval, dan kan je jezelf op een wachtlijst inschrijven,
voor wanneer ChatGPT beslist om meer proefpersonen toe
te laten. Het werd
algemeen verwacht, en verleden week was het zover:
ChatGPT heeft zijn eigen zoekmachine gelanceerd, die je
bereiken kan via chatgpt.com/search - tenminste, als je
tot een van de 10.000 testgebruikers behoort, die een
uitnodiging gekregen hebben. Was dat niet voor jou het
geval, dan kan je jezelf op een wachtlijst inschrijven,
voor wanneer ChatGPT beslist om meer proefpersonen toe
te laten.
Wat je dan te zien krijgt, hebben wij dus enkel uit
tweede hand. Je zou namelijk een zoekvak zien met de zin
daaronder: "What are you looking for?". De resultaten
zijn voornamelijk korte samenvattingen die een context
bieden op jouw vraag, met een link naar de website waar
deze informatie gevonden werd - een beetje wat Google
momenteel ook doet bij bepaalde zoekopdrachten.
Bij de zoekmachine van OpenAI zit er ook een zijbalk
bij, met meer verwante links naar het antwoord. En je
kan opvolg-vragen stellen. De bronnen waar het al deze
informatie haalt, zou naar eigen zeggen afkomstig zijn
van partners zoals Wall Street Journal, The Associated
Press en Vox Media. Uitgevers die willen meewerken aan
het project, zullen kunnen bepalen hoe hun content eruit
ziet in de zoekresultaten. Bovendien zouden zij zelfs
kunnen bepalen dat hun content wel vermeld wordt in de
zoekresultaten, maar dat die niet gebruikt wordt om de
OpenAI modellen te trainen.
Een voorbeeld moet het concreet maken: "music festivals
in Boone North Carolina in august" gaf een samenvatting
met verschillende festivals, met een korte samenvatting
van elk festival, en een link naar de website van het
evenement. Links was er een zijbalk met links van blogs,
nieuwssites en andere bronnen.
ChatGPT heeft wel aangekondigd dat de zoekresultaten op
termijn zullen samensmelten met ChatGPT zelf.
Dé hamvraag: zullen de gebruikers massaal overschakelen
naar de zoekbot van ChatGPT, of blijven zij Google
trouw? Veel zal afhangen van de integratie van deze
nieuwe zoekmachine in allerlei producten. Microsoft en
OpenAI zijn twee handen op één buik, terwijl Google en
Android goede maatjes zijn. Google betaalt bovendien
verschillende fabrikanten, o.a. Apple, veel geld om zijn
zoekmachine als standaard in te zetten. Om dus op te
volgen!
https://www.theverge.com/2024/7/25/24205701/openai-searchgpt-ai-search-engine-google-perplexity-rival
https://www.theverge.com/2024/7/26/24206582/searchgpt-google-reddit-ai-search-alexa-vergecast
https://www.wsj.com/tech/ai/openai-search-engine-searchgpt-97771f86?st=x9kc5z46ujg920r&reflink=desktopwebshare_permalink
X: GEEN LINKS MEER IN ANTWOORDEN (ALS JE DAT WIL) EN
JOUW POSTINGS WORDEN VOER VOOR GROK
 Twee
berichten over X, het voormalige Twitter. Dat, sinds het
door Elon Musk gekocht werd, soms rare bochten maakt.
Het eerste bericht zal je misschien al doen fronsen:
voortaan zullen links in antwoorden niet meer mogelijk
zijn. Het is te zeggen: als jij, de persoon die de post
geplaatst heeft, dat wil. X wil daarmee spam in de
antwoorden aan banden leggen. En dat is eigenlijk een
goede maatregel, als je het ons vraagt, want spammers
maken gretig gebruik van postings die populair zijn, om
een "antwoord" te plaatsen dat alleen maar reclame is
voor hun eigen product. Wanneer zij geen link meer
kunnen plaatsen naar dat product, heeft het voor die
spammers geen zin meer om deze methode te misbruiken.
Wij zijn voor! (1) Twee
berichten over X, het voormalige Twitter. Dat, sinds het
door Elon Musk gekocht werd, soms rare bochten maakt.
Het eerste bericht zal je misschien al doen fronsen:
voortaan zullen links in antwoorden niet meer mogelijk
zijn. Het is te zeggen: als jij, de persoon die de post
geplaatst heeft, dat wil. X wil daarmee spam in de
antwoorden aan banden leggen. En dat is eigenlijk een
goede maatregel, als je het ons vraagt, want spammers
maken gretig gebruik van postings die populair zijn, om
een "antwoord" te plaatsen dat alleen maar reclame is
voor hun eigen product. Wanneer zij geen link meer
kunnen plaatsen naar dat product, heeft het voor die
spammers geen zin meer om deze methode te misbruiken.
Wij zijn voor! (1)
Een tweede bericht echter roept vragen op - tenminste,
op het eerste gezicht. Het draait namelijk om de chatbot
die X ontwikkelt, Grok. Ook die heeft materiaal nodig,
modellen, waarop het zijn AI kan trainen. De postings
van de gebruikers op X zijn uiteraard handig daarvoor.
Maar X heeft dat wel op een manier aangepakt die je op
zijn minst onhandig kan noemen, en zelfs regelrecht in
strijd met sommige regelgeving. In de instellingen heeft
X namelijk een nieuwe Data Sharing optie standaard op
actief gezet. Waardoor elke gebruiker er standaard mee
instemt dat zijn/haar data gebruikt worden om de AI te
voeden. Wat tot heel wat gemor geleid heeft, uiteraard.
Je kan deze optie zelf uitzetten - bij Engadget vind je
tips hoe je dat moet doen. (2)
Bij DTNS vonden wij wel een bedenking. X is een uniek
sociaal netwerk, waar je nog altijd terecht kan voor
nieuws, persoonlijke verhalen, voor informatie... maar
ook voor echt te gekke dingen. Zo gek zelfs dat er een
"Weird Twitter" term ontstaan is, met memes, puzzels en
referenties, die geen enkele zin hebben. Denk maar aan
Rickrolling.
Dat aspect van Twitter, pardon: X, roept toch wel vragen
op: hoe zal dat Large Language Model van Grok eruit
zien, met al die zottigheden?
Maar misschien zal dat Elon Musk worst wezen?
https://x.com/nima_owji/status/1814325667929989533
https://www.engadget.com/heres-how-to-stop-groks-ai-models-using-your-tweets-for-training-161041266.html?src=rss
https://www.windowscentral.com/software-apps/twitter/elon-musk-grok-ai-secretly-trains-with-your-x-data
CALL CASTING EN HET DELEN VAN JE INTERNETVERBINDING
OP ANDROID TOESTELLEN WORDT NOG GEMAKKELIJKER
 In mei
werden twee nieuwe functies aangekondigd op de I/O
conferentie, die eigenlijk de eerste zouden zijn van
nieuwe cross-device diensten die het gemakkelijker
moeten maken om van het ene Android toestel naar het
andere toestel over te schakelen. In mei
werden twee nieuwe functies aangekondigd op de I/O
conferentie, die eigenlijk de eerste zouden zijn van
nieuwe cross-device diensten die het gemakkelijker
moeten maken om van het ene Android toestel naar het
andere toestel over te schakelen.
Met Call casting zou een videogesprek van het ene
toestel naar het andere naadloos kunnen overzetten, op
voorwaarde uiteraard dat je op beide toestellen dezelfde
Google account hebt. Concreet zou je dus een
videogesprek dat je in een dergelijke app opstart,
kunnen doorschakelen naar een ander toestel, waarbij de
app je een lijst geeft van toestellen in je omgeving
waarnaar je het gesprek kan casten. Momenteel echter
enkel mogelijk voor Google Meet.
Met Internet Sharing kan je automatisch toegang tot je
hotspot delen met je eigen toestellen. Ook hier weer
moet je dezelfde Google Account hebben op de
verschillende toestellen, zoals een Chromebook en
Android toestel. Uiteraard moet Bluetooth actief zijn,
evenals de locatiegegevens van de toestellen. Met
Samsung toestellen werkt het echter niet, althans
momenteel niet.
https://www.engadget.com/googles-first-cross-device-sharing-features-for-android-now-rolling-out-123019094.html?src=rss
ANTHROPIC ZOU ANTI-SCHRAAP REGELS NIET EERBIEDIGEN
VOLGENS IFIXIT EN FREELANCER
 Telkens en
telkens komt de klacht terug: bedrijven die een AI
ontwerpen eerbiedigen de regels voor auteursrechtelijk
beschermde content niet, wanneer zij content gaan
"schrapen" van het internet. Nochtans kan een bedrijf
dat content op het internet publiceert, in zijn
robots.txt duidelijk aangeven dat de content niet
geschraapt mag worden. Telkens en
telkens komt de klacht terug: bedrijven die een AI
ontwerpen eerbiedigen de regels voor auteursrechtelijk
beschermde content niet, wanneer zij content gaan
"schrapen" van het internet. Nochtans kan een bedrijf
dat content op het internet publiceert, in zijn
robots.txt duidelijk aangeven dat de content niet
geschraapt mag worden.
Verleden week gaven twee websites (Freelancer en iFixit)
aan dat zij vastgesteld zouden hebben dat Anthropic, het
bedrijf achter de Large Language Modellen van Claude,
die robots.txt negeerde en dat de robots van Anthropic
wel degelijk data van hun websites geschraapt hebben.
Een woordvoerder van Freelancer heeft aan The
Information verklaart dat de Claudebot van Anthropic
echt de agressiefste schraper is van allemaal. Hun
website zo maar liefst 3,5 miljoen bezoekjes gekregen
hebben van die crawler in amper een paar uren tijd, wat
vijf keer meer is dan de crawler doet die op de tweede
plaats staat qua bezoekjes.
Volgens iFixit zou de bot van Anthropic de servers van
iFixit in 24 uur tijd een miljoen keer bezocht hebben.
En dat betekent niet alleen dat de bot de content
gebruikt zonder ervoor te betalen, maar dat de bot de
systeembronnen van die servers belast. De woordvoerder,
Kyle Wien, besloot om Anthropic een lesje te leren. Het
vroeg aan Claude, de AI van Anthropic, wat hij zou
moeten doen wanneer hij een machine learning model aan
het trainen was, en een tekst vond in de
gebruiksvoorwaarden die het schrapen van teksten
verbood. En het antwoord van Claude was duidelijk:
"Gebruik die content niet".
Meer bij Engadget, en een mooie discussie bij Slashdot.
https://www.engadget.com/websites-accuse-ai-startup-anthropic-of-bypassing-their-anti-scraping-rules-and-protocol-133022756.html?src=rss
https://tech.slashdot.org/story/24/07/25/2041247/ifixit-ceo-takes-shots-at-anthropic-for-hitting-our-servers-a-million-times-in-24-hours?utm_source=rss1.0mainlinkanon&utm_medium=feed
NA HET DEBACLE MET CROWDSTRIKE: FSF STELT VRAGEN BIJ
AUTOMATISCHE UPDATES
 De gevolgen van
een fout bij een update van cloud-beveiligingssoftware
Crowdstrike waren wereldwijd te voelen. En eigenlijk was
dat hele incident te wijten aan een bestandje van amper
40k, een update die onvoldoende getest was. De gevolgen van
een fout bij een update van cloud-beveiligingssoftware
Crowdstrike waren wereldwijd te voelen. En eigenlijk was
dat hele incident te wijten aan een bestandje van amper
40k, een update die onvoldoende getest was.
Reden voor de Free Software Foundation om zich vragen te
stellen over automatische updates. En wellicht heb jij
je daar ook al vragen over gesteld. Want heel veel
programma's installeren die automatisch, en er bestaat
altijd een risico dat er iets gebroken wordt door zo'n
update. Een automatische update is anderzijds ook aan te
raden, omdat gebruikers die update anders zouden
uitstellen.
Ethisch is er dus niets mis met automatische updates -
tenminste: wanneer de gebruiker geïnformeerd wordt over
de beslissing om die updates automatisch te ontvangen.
En die weet meestal niet in welk avontuur hij zich
stort.
Bij Slashdot volgt hierover een heel artikel waarom het
zo'n risico inhoudt dat zo veel belangrijke diensten
over de hele wereld, afhangen van één enkele distributie
van één enkel besturingssysteem, gemaakt door één enkel
bedrijf in Redmond. Zou het niet beter zijn dat
verschillende bedrijven verschillende versies gebruiken
van GNU/Linux, met elk hun eigen beveiligingsteams?
Dat is natuurlijk open voor discussie. Want er is ook
nog het probleem van interoperabiliteit, zo menen wij.
En het is gemakkelijker dat alle systemen naadloos
samenwerken (met de risico's vandien weliswaar, zoals
Crowdstrike). Maar zijn er niet meer risico's dat elke
update bij elk ander systeem weer iets breken kan.
Bij Slashdot een interessante discussie daarover: is het
idee van de Free Software Foundation te utopisch?
https://en.wikipedia.org/wiki/Free_Software_Foundation
https://news.slashdot.org/story/24/07/28/2349222/after-crowdstrike-outage-fsf-argues-theres-a-better-way-forward
AI: PERPLEXITY WIL INKOMSTEN DELEN MET BRONNEN
 Een van de
minder bekende AI-tools is Perplexity. Dat is een
zoekmachine die zowel zoekt als waar je een gesprek kan
voeren, uiteraard gebaseerd op AI. En je krijgt de
antwoorden in een natuurlijke taal, waarbij ook verwezen
wordt naar de bronnen waarop dat antwoord gebaseerd is. Een van de
minder bekende AI-tools is Perplexity. Dat is een
zoekmachine die zowel zoekt als waar je een gesprek kan
voeren, uiteraard gebaseerd op AI. En je krijgt de
antwoorden in een natuurlijke taal, waarbij ook verwezen
wordt naar de bronnen waarop dat antwoord gebaseerd is.
Tot nu werkte Perplexity met een freemium model,
waarbij de gratis versie antwoorden geeft op basis van
het eigen LLM van het bedrijf, terwijl de betalende
versie daarvan je ook toegang geeft tot GPT-4, Claude
3.5, Mistral Large, Llama 3 en het experimentele model
van Perplexity zelf (1)
Deze week heeft Perplexity nog een ander financieel
model aangekondigd: het zal inkomsten uit advertenties
gaan delen met uitgevers. Alvast Time, Der Spiegel,
Fortune, Entrepreneur, The Texas Tribune en WordPress
van Automattic zijn aan boord.
Concreet zal Perplexity een vast percentage met hen
delen van de inkomsten die het haalt uit de advertenties
die geplaatst worden naast de artikels van die
uitgevers, in de nieuwe "Keep Exploring" functie.
En daar wordt het wel erg intrigerend. Merken kunnen
betalen om specifieke follow-up vragen te suggereren,
een optie die later uitgerold wordt wanneer het
programma in gang gezet wordt. Perplexity overweegt ook
nieuwe advertentieformats, zoals een video unit bovenaan
de pagina.
Het is duidelijk dat Perplexity het tij wil keren, nadat
het door Forbes, Wired en CondéNast ervan beschuldigd
werd dat het content van hun site schraapte, ondanks dat
dit in de robots.txt verboden was. Perplexity wil naar
eigen zeggen het spel zuiver spelen, en een beduidend
deel van zijn inkomsten delen met de uitgevers "een
dubbel-cijfer", dus minstens 10%. En dat terwijl Google
de uitgevers eigenlijk niets betaalt, wat lange tijd een
doorn in het oog is geweest van de uitgevers. En ook de
reden waarom Google nog altijd geen nieuws uit België
brengt (of liever: mag brengen) na een proces met de
Franstalige Belgische uitgevers.
Meer bij Engadget en The Verge.
https://www.engadget.com/perplexity-will-put-ads-in-its-ai-search-engine-and-share-revenue-with-publishers-130052289.html?src=rss
https://www.theverge.com/2024/7/30/24208979/perplexity-publishers-program-ad-revenue-sharing-ai-time-fortune-der-spiegel
https://en.wikipedia.org/wiki/Perplexity.ai
META ROLT ZIJN AI STUDIO UIT
 Na een beperkte
test eind verleden jaar, brengt Meta nu zijn AI Studio
uit. Dat is een reeks tools waarmee creators op
Instagram, die in de VS gebaseerd zijn, een AI persona
kunnen creëren die henzelf vertegenwoordigt, een
virtuele dubbelganger eigenlijk. Zo'n gepersonaliseerde
chatbot kan dan vragen beantwoorden en met de volgers en
fans van die creator chatten. Na een beperkte
test eind verleden jaar, brengt Meta nu zijn AI Studio
uit. Dat is een reeks tools waarmee creators op
Instagram, die in de VS gebaseerd zijn, een AI persona
kunnen creëren die henzelf vertegenwoordigt, een
virtuele dubbelganger eigenlijk. Zo'n gepersonaliseerde
chatbot kan dan vragen beantwoorden en met de volgers en
fans van die creator chatten.
De bedoeling is dat creators met heel veel fans, en die
heel veel vragen krijgen, die te laten antwoorden door
hun virtueel persoontje. De chatbot zou dus eigenlijk
een extensie worden van henzelf. De antwoorden worden
gehaald uit de commentaren bij Reels, de ondertiteling
en de transcripts ervan. Ook kunnen de creators zelf
instructies toevoegen of links.
Een leuk idee. Maar toch een beetje sneu voor de fan.
Die zal altijd het raden hebben of het nu de échte
creator is die hen te woord staat, of die virtuele
persona...
https://www.engadget.com/instagram-creators-can-now-make-ai-doppelgangers-to-chat-with-their-followers-220052768.html
META STELT SEGMENT ANYTHING 2 VOOR
 Op de SIGGRAPH
conferentie heeft Mark Zuckerberg, CEO van Meta, de
laatste versie voorgesteld van Segment Anything 2 of
SA2. Dat is een machine learning model, dat heel snel en
accuraat een specifiek iets kan identificeren en
uitknippen in een afbeelding. Op de SIGGRAPH
conferentie heeft Mark Zuckerberg, CEO van Meta, de
laatste versie voorgesteld van Segment Anything 2 of
SA2. Dat is een machine learning model, dat heel snel en
accuraat een specifiek iets kan identificeren en
uitknippen in een afbeelding.
Segmentering heet dat, en het omschrijft een visueel
model dat een afbeelding kan onderzoeken en kan "zien"
dat er bijvoorbeeld zowel een hond, een bal als een boom
in staan. En dat dat drie aparte dingen zijn. Ook
wanneer die boom achter de hond staat, zou de techniek
kunnen onderscheiden dat de boom achter de hond staat,
en niet een boom zien die uit een hond groeit...
Deze nieuwe versie werkt standaard ook met video's, niet
enkel met stilstaande beelden. Iedereen zal het kunnen
gebruiken en het is een open model. Meta heeft een grote
database met toelichtingen gedeeld van 50.000 video's
die het gemaakt had, maar het had ook nog een andere
database van meer dan 100.000 video's die naar eigen
zeggen enkel voor intern gebruik waren, en die eveneens
voor de training gebruikt werd. Die grotere database zal
echter niet publiek gemaakt worden.
Je vindt een demo van Meta op de tweede link, en het
leuke is dat je daar zelf mee aan de slag kan gaan.
https://techcrunch.com/2024/07/29/zuckerberg-touts-metas-latest-video-vision-ai-with-nvidia-ceo-jensen-huang/
https://sam2.metademolab.com/
ADVANCED VOICE MODE VAN OPENAI
 In mei dit jaar gaf OpenAI een demo van zijn
advanced voice mode, een artificiële intelligentie die
in real time werkt, een gesproken interface tussen g In mei dit jaar gaf OpenAI een demo van zijn
advanced voice mode, een artificiële intelligentie die
in real time werkt, een gesproken interface tussen g ebruikers
en de AI. Dit in tegenstelling tot een vorige versie,
die gebaseerd was op het Whisper systeem - daar werd
namelijk eerst audio naar tekst omgezet, en dan terug
naar audio. De nieuwe versie is echter gebaseerd op het
Omnimodel, dat real-time spraakherkenning gebruikt en
antwoorden genereert zonder dat er tekst-gebaseerde
tussenstappen nodig zijn (1) ebruikers
en de AI. Dit in tegenstelling tot een vorige versie,
die gebaseerd was op het Whisper systeem - daar werd
namelijk eerst audio naar tekst omgezet, en dan terug
naar audio. De nieuwe versie is echter gebaseerd op het
Omnimodel, dat real-time spraakherkenning gebruikt en
antwoorden genereert zonder dat er tekst-gebaseerde
tussenstappen nodig zijn (1)
Alleen: er ontstond wat controverse rond deze AI. Omdat
een van de stemmen die in de demo zaten, verdacht veel
leek op die van Scarlett Johansen, de actrice die haar
stem gaf aan een AI assistent in de film Her. (1)
Uit dat debacle heeft OpenAI zijn lessen getrokken. De
nieuwe versie van die AI werd enige tijd onderbroken,
omdat OpenAI mogelijk misbruik wilde voorkomen. Daarvoor
werden 100 mensen ingeschakeld die allerlei mogelijke
manieren moesten bedenken om OpenAI te misbruiken, zodat
de tool manieren op zijn beurt manieren kon bedenken om
dat misbruik te voorkomen.
Zo werden er nieuwe filters toegevoegd, die nog strenger
bepaalde verzoeken gaan blokkeren - denk aan het
genereren van muziek en audio waarop auteursrechten
berusten. De AI werkt met vier stemmen, en OpenAI
verzekert dat het er alles aan gedaan heeft zodat de
tool de stem van andere mensen niet kan nabootsen (dus:
geen zinnen zeggen in de stem van Arnold Schwarzenegger
bijvoorbeeld).
Bij deze versie kan je de "spreker" onderbreken, en hij
kan antwoorden met enige vertraging. Voorlopig wordt de
tool enkel uitgerold naar een beperkt deel van de
betalende gebruikers, en deze herfst volgt dan een
uitrol naar alle ChatGPT Plus gebruikers.
https://www.theverge.com/2024/7/30/24209650/openai-chatgpt-advanced-voice-mode
https://www.theainavigator.com/blog/what-is-chatgpt-s-advanced-voice-mode
https://www.theverge.com/2024/5/13/24155652/chatgpt-voice-mode-gpt4o-upgrades
CANVA VOEGT OOK LEONARDO.AI TOE AAN ZIJN GROEIEND
AANBOD
 In de
wereld van de beeldbewerkers was het al Photoshop wat de
klok sloeg. Maar de laatste maanden rukte een concurrent
heel fel op: Canva. Ook dat is een grafisch
ontwerpplatform waarmee je afbeeldingen, presentaties,
posters, documenten en andere visual kan creëren voor
sociale media. Het grote succes van Canva is dat het
basis platform gratis te gebruiken is - naast uiteraard
ook betaalde formules zoals Canva Pro en Canva for
Enterprise, dat je meer mogelijkheden biedt. In de
wereld van de beeldbewerkers was het al Photoshop wat de
klok sloeg. Maar de laatste maanden rukte een concurrent
heel fel op: Canva. Ook dat is een grafisch
ontwerpplatform waarmee je afbeeldingen, presentaties,
posters, documenten en andere visual kan creëren voor
sociale media. Het grote succes van Canva is dat het
basis platform gratis te gebruiken is - naast uiteraard
ook betaalde formules zoals Canva Pro en Canva for
Enterprise, dat je meer mogelijkheden biedt.
De laatste jaren breidde het platform zijn mogelijkheden
flink uit door overnames. In 2019 nam het bijvoorbeeld
Pixabay en Pexels over, twee gratis stockfotosites.
Gevolgd in 2021 door een overname van Kaleido.ai en het
Tsjechische smartpockups. En begin dit jaar volgde dan
het design platform Affinity.
En deze week kondigde Canva aan zijn platform nog verder
te willen uitbreiden met een nieuwe overname:
Lenorado.ai. Dat is een Australisch bedrijf waar je
generatieve AI-content kan aanmaken. Door die overname
zal de Canva suite tools dus ook nieuwe
tekst-naar-afbeelding en tekst-naar-video generating
tools bevatten, die je naar je eigen hand kan zetten.
Net zoals bij de overname van Affinity belooft Canva dat
Leonardo.ai zal blijven bestaan als een zelfstandig
webplatform. Maar de technologie van Leonardo.ai zal wel
spoedig geïntegreerd worden in de huidige suite van
Canva, de Magic Studio producten, waartoe ook de Magic
Media image en video generator behoren.
https://nl.wikipedia.org/wiki/Canva
https://www.theverge.com/2024/7/30/24209421/canva-leonardo-generative-ai-platform-acquisition-design-software
GOOGLE MAPS WORDT STEEDS MEER ALS WAZE… maar Waze
is zijn eigendom. Is dit een geval van kannibalisme?
Feit is in elk geval dat Google  Maps enkele
verbeteringen toegevoegd heeft aan zijn eigen bestaande
functies - maar dat toch ook Waze, dat nog altijd een
aparte app is, ook verbeteringen krijgt. Het is dus niet
zo dat Google de Waze app aan het uithongeren is. Maps enkele
verbeteringen toegevoegd heeft aan zijn eigen bestaande
functies - maar dat toch ook Waze, dat nog altijd een
aparte app is, ook verbeteringen krijgt. Het is dus niet
zo dat Google de Waze app aan het uithongeren is.
Concreet gaat het om de integratie van de belangrijkste
functies van Waze in Maps. Zo kan je gemakkelijker
incidenten melden, doordat er grotere icoontjes zijn om
jouw update te melden, denk aan een afgesloten weg,
werken onderweg, flitscamera's, aanwezigheid van
politie. Het is nog altijd zo dat andere chauffeurs die
incidenten met een enkele tik op het scherm kunnen
bevestigen. Verder krijgt Google Maps betere informatie
over waar je de ingang van een gebouw vindt, wanneer je
dat nadert. En Google zal je ook tonen waar je in de
omgeving kan parkeren.
Waze van zijn kant biedt de mogelijkheid om nieuwe
soorten verkeerscamera's te melden, zoals camera's die
melden wanneer je in de busvak rijdt, of camera's die
speuren naar chauffeurs die zonder veiligheidsgordel
rijden of die sms'en tijdens het rijden. Er komt ook een
nieuwe aparte ervaring met informatie over evenementen
zoals een marathon, een concert, een voetbalwedstrijd.
De app vertelt je dan welke wegen afgesloten zijn,
wanneer bijvoorbeeld die afsluiting wegen betreft nabij
de plek waar je werkt, je thuisadres, of een plek
waarheen je recent geweest bent.
Knappe verbeteringen, als je het ons vraagt!
https://www.theverge.com/2024/7/31/24209969/google-maps-destination-guidance-waze-camera-events
https://www.engadget.com/google-makes-it-easier-to-remove-explicit-deepfakes-from-its-search-results-130058499.html?src=rss
AI ASSISTENT VAN META HALLUCINEERT
 Verschillende
gebruikers van de AI assistent van Meta merkten iets gek
op: gevraagd naar informatie over de aanslag op
voormalig Amerikaans president Donald Trump, beweerde de
AI dat die niet gebeurd was. Verschillende
gebruikers van de AI assistent van Meta merkten iets gek
op: gevraagd naar informatie over de aanslag op
voormalig Amerikaans president Donald Trump, beweerde de
AI dat die niet gebeurd was.
En dat dergelijke fouten, de "hallucinaties", nu eenmaal
inherent zijn aan àlle generatieve AI-systemen. Het is
in elk geval een groot probleem, want dit vermindert de
betrouwbaarheid van berichtgeving bij grote
incidenten.(1)
Ook Google kreeg te maken met een klacht, ditmaal van
Elon Musk, die beweerde dat autocomplete in de Google
zoekmachine een negatieve rol gespeeld zou hebben in de
Amerikaanse verkiezingen (2)
https://www.theverge.com/2024/7/30/24210108/meta-trump-shooting-ai-hallucinations
https://www.engadget.com/the-morning-after-google-dismisses-elon-musks-claim-that-autocomplete-interfered-in-the-election-111558485.html?src=rss
BELGISCHE ONDERZOEKERS VINDEN GROOT PRIVACY-RISICO IN
ZES DATINGAPPS
 TechCrunch meldt
dat een groep onderzoekers van de KU Leuven vastgesteld
hebben dat zes populaire datingapps een probleem hebben.
En dat mensen met slechte bedoelingen van dat probleem
misbruik kunnen maken om de bijna exacte locatie van
andere gebruikers te weten te komen. TechCrunch meldt
dat een groep onderzoekers van de KU Leuven vastgesteld
hebben dat zes populaire datingapps een probleem hebben.
En dat mensen met slechte bedoelingen van dat probleem
misbruik kunnen maken om de bijna exacte locatie van
andere gebruikers te weten te komen.
Het gaat om Hinge, Happn, Bumble, Grindr, Badoo en
Hilly. Die vertoonden namelijk een soort van
trilateratie - een technologie waarbij je de coördinaten
kan bepalen van het punt waar de ontvanger van een
GPS-signaal zich bevindt, aan de hand van de afstanden
van dit punt tot enkele gekende punten. (1)
Niet alle apps konden even exact de locatie bepalen via
deze technologie, maar Grindr bijvoorbeeld kon dat wel.
En in dat geval zou een gebruiker met slechte
bedoelingen de locatie van een andere gebruiker op 2
meter na kunnen bepalen.
Sommige van deze apps hebben ondertussen hun app
aangepast, andere hebben verzekerd dat het misschien wel
mogelijk zou zijn om trilateratie toe te passen, maar
dat het onmogelijk zou zijn om dit te misbruiken voor
een aanval.
Meer bij Engadget, TechCrunch en de wetenschappelijke
paper.
https://www.ikhebeenvraag.be/mvc/vraag/5766/Wat-is-trilateratie-En-hoe-werkt-het
https://www.engadget.com/belgian-researchers-found-a-huge-privacy-hole-in-six-dating-apps-223227855.html?src=rss
https://techcrunch.com/2024/07/31/bumble-and-hinge-allowed-stalkers-to-pinpoint-users-locations-down-to-2-meters-researchers-say/
https://lepoch.at/files/dating-apps-usesec24.pdf
REDDIT MEENT HET: ENKEL WIE BETAALT OM TE SCHRAPEN
KRIJGT NOG TOEGANG TOT DE CONTENT
 Eerder
deze week kon je lezen dat Perplexity een verfrissende
manier aankondigde om contentmakers wél te betalen,
wanneer hun materiaal gebruikt wordt door zijn AI. Een
besef dat stilaan begint door te dringen, dat content
betaald moet worden, maar dat door Google volledig
onderuit gehaald werd. Eerder
deze week kon je lezen dat Perplexity een verfrissende
manier aankondigde om contentmakers wél te betalen,
wanneer hun materiaal gebruikt wordt door zijn AI. Een
besef dat stilaan begint door te dringen, dat content
betaald moet worden, maar dat door Google volledig
onderuit gehaald werd.
Sociale nieuwswebsite Reddit heeft in elk geval begrepen
dat de content op haar site geld waard is. Het heeft al
financiële afspraken gemaakt met Google Search en
SearchGPT, in ruil waarvoor die de data op de site mogen
gebruiken om hun modellen te trainen. Met Microsoft,
Anthropic en Perplexity echter heeft het nog geen
akkoorden kunnen sluiten, en daarom blokkeert Reddit
die: via de robots.txt wordt aangegeven dat de crawlers
van die bedrijven geen content meer mogen schrapen.
In een artikel bij The Verge beklaagt Reddit er zich
over dat Microsoft desondanks nog altijd Reddit data
gebruikt voor zijn AI en zijn Bing zoekmachine, en dat
de data van Reddit zelfs via de Bing API doorverkocht
zouden worden naar andere zoekmachines.
Meer bij The Verge.
https://www.theverge.com/2024/7/31/24210565/reddit-microsoft-anthropic-perplexity-pay-ai-search
 |
Hoe bedenken ze het
Soft- en
hardwarefabrikanten met nieuw en/of
beter!
|
SECURE BOOT IS
ERNSTIG GECOMPROMITTEERD
 Als je het niet
wist: Secure Boot is een technologie die het
opstartproces van jouw computer beschermt tegen
beveiligingsaanvallen via schadelijke code, zoals
malware en ransomware. Want als dergelijke malware
tijdens het opstarten geïnstalleerd zou worden, kan het
daarna niet meer opgespoord worden door je
besturingssysteem. Als je het niet
wist: Secure Boot is een technologie die het
opstartproces van jouw computer beschermt tegen
beveiligingsaanvallen via schadelijke code, zoals
malware en ransomware. Want als dergelijke malware
tijdens het opstarten geïnstalleerd zou worden, kan het
daarna niet meer opgespoord worden door je
besturingssysteem.
Een prachtige bescherming - maar helaas blijkt die niet
meer 100% veilig te zijn. Het bedrijf Binary heeft
namelijk twee verwante manieren ontdekt waardoor
SecureBoot gecompromitteerd kan worden.
De eerste is mogelijk doordat de Platform Key, die
Secure Boot beveiligt, op GitHub gepost werd in een
versleuteld bestand met een toegangscode van amper 4
tekens - gemakkelijk te kraken dus. De tweede omdat
verschillende fabrikanten bij het product dat zij op de
markt brengen, een testcode gebruiken van een bedrijf
dat AMI heet, ondanks het feit dat de Platform Key in
deze testcode duidelijk de string "DO NOT TRUST" of "DO
NOT SHIP" vermeldde.
Meer dan 200 modellen van 5 grote fabrikanten zijn
getroffen. Maar er is een lichtpuntje: het zijn geen
toestellen voor gewone gebruikers, en veel van die
toestellen worden niet meer op de markt gebracht.
Bedrijven doen er best aan om dit even na te kijken. Als
de fabrikant van hun toestellen geen update van de
firmware aanbiedt, dan doen die bedrijven er goed aan om
de betroffen toestellen gewoon te vervangen, om erger te
vermijden.
https://arstechnica.com/security/2024/07/secure-boot-is-completely-compromised-on-200-models-from-5-big-device-makers/
EXOSKELET MAAKT JE RUGZAK PAKKEN LICHTER
 Een exoskelet is
werd oorspronkelijk bedacht als medisch hulpmiddel, voor
mensen met een verlamming. Het werd uitgebreid naar
mensen die een job moeten uitvoeren die hun lichaam
zwaar belast, om hun taak te verlichten. En nu blijkt
het ook vrijetijdstoepassingen te hebben Een exoskelet is
werd oorspronkelijk bedacht als medisch hulpmiddel, voor
mensen met een verlamming. Het werd uitgebreid naar
mensen die een job moeten uitvoeren die hun lichaam
zwaar belast, om hun taak te verlichten. En nu blijkt
het ook vrijetijdstoepassingen te hebben
Het bedrijf Arc'teryx heeft een partnerschap afgesloten
met Sip, een van de spin-offs van Google X Labs. Met als
doel toepassingen te maken van zo'n exoskelet, naar
activiteiten in je vrije tijd.
En zo ontstond de MO/GO broek, een broek met op het
kniegewricht een lichtgewicht elektrische motor, die de
kracht van het been van een wandelaar kan verhogen,
wanneer die bergopwaarts stapt, maar ook de impact van
stappen kan verminderen wanneer die neerdaalt.
MO/GO staat voor mountain goat. De broek in dit geval
weegt 3,18 kg, dus toch ook een gewicht dat je moet
meesleuren. Dat is inbegrepen een batterij die drie uur
mee kan, en die je kan herladen.
Meer over deze exoskelet-broek bij The Verge. Maar
eerlijk: is het doel een trekker die een bergwandeling
onderneemt, niet juist zijn sportiviteit,
uithoudingsvermogen te testen? En is dit niet wat
valsspelen - net zoals je aan een koers zou deelnemen
met een elektrische fiets? Of zou gaan gewichtheffen met
een exoskelet aan je armen en schouders.?
https://www.theverge.com/2024/7/29/24208615/arcteryx-skip-google-x-labs-mogo-hiking-exoskeleton
MAAK KENNIS MET JE AI-VRIEND, FRIEND
 Er wordt dapper
gezocht naar een nieuwe vormfactor voor de
AI-toepassingen. Want nu moet je voortdurend je
smartphone te boven halen. En dat moet simpeler kunnen,
vooral wanneer de meeste AI's kunnen luisteren, spreken
en zien. Er wordt dapper
gezocht naar een nieuwe vormfactor voor de
AI-toepassingen. Want nu moet je voortdurend je
smartphone te boven halen. En dat moet simpeler kunnen,
vooral wanneer de meeste AI's kunnen luisteren, spreken
en zien.
De brillen zoals de Ray Ban van Meta zijn al zo'n nieuwe
vormfactor - en die lijkt aan te slaan. Een andere optie
is de Pin van Humane, een broche - maar die is niet
alleen niet aantrekkelijk, maar lijkt ook niet zo best
te werken.
Een bedrijf, dat de steun krijgt van de oprichters van
Solana, Perplexity en Zfellows, heeft nog een andere
vormfactor uitgebracht: een hanger, die het simpelweg
"Friend" noemt. Die Friend is via Bluetooth met je
smartphone verbonden, en luistert de hele tijd naar jou.
De Friend kan niet alleen antwoorden op vragen die jij
stelt, wanneer je een knop indrukt, maar hij kan ook
proactief dingen zeggen, die de Friend meent dat gepast
zijn. Bijvoorbeeld je geluk wensen wanneer je gaat
solliciteren voor een job.
Is dat geen gevaar voor je privacy, zo'n toestel dat
altijd meeluistert? Dat zou moeten meevallen, want alle
data worden op jouw smartphone verwerkt en gaan niet
naar de cloud. Het toestel zou in januari 2025 in de
winkel moeten liggen aan de prijs van $99.
https://techcrunch.com/2024/07/30/friend-is-an-ai-companion-backed-by-founders-of-solana-perplexity-and-zfellows/

|
Het oor wil ook wat!
Audio op het Internet
|
DE DIKKE DELVAUX
 Net zoals
de Dikke Vandale hét naslagwerk is voor teksten, is de
Dikke Delvaux dat voor popmuziek in Vlaanderen.
Ontelbaar zijn de verhalen over Vlaamse artiesten, welke
artiest speelde in welke band en waar je die later weer
terugvindt. Sappig verteld, met heel veel anekdotes.
Iets oudere lezers zullen hiervan smullen. Maar ook
jonge lezers zullen hun gading vinden, want veel van die
"oudjes" komen vaak terug in de belangstelling. Net zoals
de Dikke Vandale hét naslagwerk is voor teksten, is de
Dikke Delvaux dat voor popmuziek in Vlaanderen.
Ontelbaar zijn de verhalen over Vlaamse artiesten, welke
artiest speelde in welke band en waar je die later weer
terugvindt. Sappig verteld, met heel veel anekdotes.
Iets oudere lezers zullen hiervan smullen. Maar ook
jonge lezers zullen hun gading vinden, want veel van die
"oudjes" komen vaak terug in de belangstelling.
Wat te denken bijvoorbeeld van een meme rond Mario
Mathy, de "Vangelis van de Kempen"? Hij is momenteel een
hit op het internet, met een videoclip uit uit 1987 die
nu een meme werd !
https://www.vrt.be/vrtmax/podcasts/radio-1/d/dikke-delvaux/
https://www.hln.be/houthalen-helchteren/video-clip-van-synthesizer-held-mario-mathy-vanhove-gaat-na-35-jaar-wereldwijd-viraal-ik-relativeer-het-en-heb-die-periode-al-lang-afgesloten~a13cbdbf/
https://www.youtube.com/watch?v=NuW41shJm0k
WORD JE NU ECHT RIJK MET PODCASTS? HELAAS, NEEN
 Een
rapport waarover wij met de nodige voorzichtigheid
berichten. Want wij willen echt niet dat die duizenden
podcastmakers, die steengoede podcasts maken, hierdoor
afgeschrikt worden. Wellicht zullen zij al wel begrepen
hebben dat je van een podcast niet zo rijk wordt als
wanneer je als influencer duizenden volgers hebt. Maar
dit rapport geeft toch wel een heel teleurstellend beeld
van het verdienmodel van podcasts. Een
rapport waarover wij met de nodige voorzichtigheid
berichten. Want wij willen echt niet dat die duizenden
podcastmakers, die steengoede podcasts maken, hierdoor
afgeschrikt worden. Wellicht zullen zij al wel begrepen
hebben dat je van een podcast niet zo rijk wordt als
wanneer je als influencer duizenden volgers hebt. Maar
dit rapport geeft toch wel een heel teleurstellend beeld
van het verdienmodel van podcasts.
Het gaat uiteraard om een rapport uit de VS. Dat stelt,
heel cru, dat het grote geld gaat naar de grote
podcasts, die het grootste publiek hebben. De top 25
podcasts zouden namelijk de helft van de reguliere
luisteraars in de VS bereiken. De top 100 bereikt meer
dan 60% van het totale publiek voor podcasts.
In een artikel bij 9to5 wordt gesteld dat het Apple is
dat podcasts mainstream gemaakt heeft. En dat is niet de
manier waarop wij daarop terugdenken. Wij hadden toen
geen i-toestel, wel een kleine MP3-speler. En via een
app op onze Windows computer konden wij via de RSS-feed
van die podcasts, die op onze computer downloaden, en
manueel naar die MP3-speler overzetten.
Sindsdien is dat allemaal veel eenvoudiger gegaan. Maar
de bewering dat Apple met zijn iTunes en het gebruik van
RSS-feeds de podcast gemeengoed gemaakt heeft, dat
stellen wij toch in vraag, want het was verdomd moeilijk
om in iTunes de RSS-feed naar een podcast te vinden.
Maar dat terzijde - het artikel bij 9to5 Mac ging over
het verdienmodel. Grote namen gaan lopen met het meeste
luisteraars, zo stelt het artikel dat zich baseert op
cijfers van Wall Street Journal. De top 10 heeft 35% van
het totaal luisteraars in de VS. De top 100 heeft 61%
van alle luisteraars. Maar misschien is hier ook de
"long tail" een aspect om rekening mee te houden?
In elk geval: wij zijn heel dankbaar voor de vele mensen
en teams die podcasts maken waarvan wij o zo hard kunnen
genieten!
Meer beschouwingen bij 9to5Mac en WSJ.
https://9to5mac.com/2024/07/29/podcasting-getting-tougher/
https://www.wsj.com/business/media/a-few-blockbuster-podcasts-are-making-all-the-money-d9cee36ee
 TIKTOK SOUND SEARCH: ZING
EENS EEN DEUNTJE TIKTOK SOUND SEARCH: ZING
EENS EEN DEUNTJE
Een leuke nieuwe functie, helaas enkel voor een beperkt
aantal gebruikers. Op TikTok krioelt het van de liedjes,
videoclips met songs, dat het soms heel moeilijk is om
een bepaalde song terug te vinden. En daarvoor heeft
TikTok nu een leuke oplossing gevonden: voortaan moet je
gewoon de muziek van de song neuriën of zingen, en het
platform zal je tonen welke song het is, en welke
video's die zong gebruiken. En dat laatste is wat deze
functie onderscheidt van een gelijkaardige tool op
YouTube: daar kan je ook zoeken naar een song door die
te zingen of neuriën, maar YouTube vertelt niet in welke
video's de song voorkomt. En ook op Shazam, de bekende
tool om songs te herkennen, want daar moet je de echte
song spelen, niet enkele maten of de song neuriën.
Meer bij Engadget.
https://www.engadget.com/tiktoks-sound-search-lets-you-find-videos-by-humming-or-singing-120029367.html?src=rss
https://www.tiktok.com/discover/sound-search?lang=en
 |
De nieuwe oogst
|
LAST24.AI
 Deze op AI gebaseerde
zoekmachine belooft dat zij je helpt om het nieuws
van vandaag beter te begrijpen. De webdienst zoekt
het internet af, kiest het belangrijkste nieuws
dat voor jou interessant is, vat de belangrijkste
punten voor jou samen in een mooie visuele
vormgeving. Deze op AI gebaseerde
zoekmachine belooft dat zij je helpt om het nieuws
van vandaag beter te begrijpen. De webdienst zoekt
het internet af, kiest het belangrijkste nieuws
dat voor jou interessant is, vat de belangrijkste
punten voor jou samen in een mooie visuele
vormgeving.
Wij wilden de webdienst uittesten, maar werden
meteen geconfronteerd met de barrière dat je moet
inloggen met je Google account. En dan.. ja, dan
haken wij af. Een nieuwe webdienst moet je nu
eenmaal anoniem kunnen uittesten, toch? Wie de
stap toch gezet heeft om in te loggen, en de
dienst uitgetest heeft, laat ons weten hoe het je
vergaan is?
[Taal: EN]
https://last24.ai/?ref=producthunt
|
PHOTOLAPSE AI
 Deze
webdienst wil je de mogelijkheid bieden om foto's
waarin jij voorkomt om te vormen tot een time
lapse, een collage van beelden waarin te zien is
hoe jij door de jaren heen veranderd bent. De AI
zorgt ervoor dat jouw gezicht doorheen al die
foto's centraal blijft in de collage. Je kan er
ook een video van maken, en met een pro account
kan je daaraan effecten toevoegen. Deze
webdienst wil je de mogelijkheid bieden om foto's
waarin jij voorkomt om te vormen tot een time
lapse, een collage van beelden waarin te zien is
hoe jij door de jaren heen veranderd bent. De AI
zorgt ervoor dat jouw gezicht doorheen al die
foto's centraal blijft in de collage. Je kan er
ook een video van maken, en met een pro account
kan je daaraan effecten toevoegen.
Je kan het geheel gratis downloaden, gebaseerd op
maximaal 200 foto's van jezelf, maar dan wel met
watermerk. Betaal je $5,99, dan wordt het
watermerk verwijderd.
[Taal: EN]
https://www.photolapseai.com/
|
OFFLIGHT: PRODUCTIEVER WORDEN
 Deze
webdienst en app belooft een hele verbetering in
je privéleven maar ook je werk. Je to-do lijstjes,
afspraken en tools om de tijd die je besteedt als
freelancer als verschillende taken, worden hier
namelijk verzameld, in een eenvoudige webapp (maar
ook verkrijgbaar als app voor Windows en Apple) Deze
webdienst en app belooft een hele verbetering in
je privéleven maar ook je werk. Je to-do lijstjes,
afspraken en tools om de tijd die je besteedt als
freelancer als verschillende taken, worden hier
namelijk verzameld, in een eenvoudige webapp (maar
ook verkrijgbaar als app voor Windows en Apple)
[Taal: EN]
https://www.offlight.work/
|
SLIMIFY: AFBEELDINGEN OPTIMALISEREN
 Met deze
webdienst kan je afbeeldingen optimaliseren voor
gebruik op het web en het mobiele toestel. De
webapp comprimeert de grootte van je afbeeldingen,
zonder te peuteren aan de kwaliteit ervan. Met deze
webdienst kan je afbeeldingen optimaliseren voor
gebruik op het web en het mobiele toestel. De
webapp comprimeert de grootte van je afbeeldingen,
zonder te peuteren aan de kwaliteit ervan.
Gewoon bestanden naar de website slepen of via het
dialoogvenster uploaden. Je kan max. 10 bestanden
per keer uploaden (.jpeg, .png, .webp).
[Taal: EN]
https://slimify.app/
|
LOFI ATC
 Een leuk
ideetje: deze webdienst combineert de live
gesprekken van de air traffic control met chill en
beat muziek. Je kan kiezen welke luchthaven je wil
(en klik je op de knop rechts, dan ga je naar de
Live ATC site met meer info over die gesprekken).
Klik je op het deuntje dat gespeeld wordt, dan
word je naar de weergave van het filmpje op
YouTube gevoerd. Ontspannend. Een leuk
ideetje: deze webdienst combineert de live
gesprekken van de air traffic control met chill en
beat muziek. Je kan kiezen welke luchthaven je wil
(en klik je op de knop rechts, dan ga je naar de
Live ATC site met meer info over die gesprekken).
Klik je op het deuntje dat gespeeld wordt, dan
word je naar de weergave van het filmpje op
YouTube gevoerd. Ontspannend.
[Taal: EN]
https://www.lofiatc.com
|
STUDIGPT: QUIZ
 Even je kennis testen?
Dat kan met deze door ChatGPT aangedreven quiz. Je
kan het onderwerp van de vragen bepalen, hoeveel
vragen je wenst te beantwoorden in de quiz, plus
de moeilijkheidsgraad. De interface van de quiz is
heel simpel en rustgevend. En je kan nadien ook
zien wat het juiste antwoord was, als je vragen
verkeerd had beantwoord. Even je kennis testen?
Dat kan met deze door ChatGPT aangedreven quiz. Je
kan het onderwerp van de vragen bepalen, hoeveel
vragen je wenst te beantwoorden in de quiz, plus
de moeilijkheidsgraad. De interface van de quiz is
heel simpel en rustgevend. En je kan nadien ook
zien wat het juiste antwoord was, als je vragen
verkeerd had beantwoord.
[Taal: EN]
https://studigpt.com/#/
|
ROME AI
 Dit is een
van de tools die op AI gebaseerd zijn, waarbij wij
wel vragen stellen. Ja, bij AI tools waar je
vragen kan stellen over een bepaald onderwerp,
krijg je tekst, die je kan lezen. Maar deze tool
beweert een stap verder te gaan, en over dat
onderwerp een heuse podcast te kunnen maken. Nu,
ik weet niet hoe het voor jou zit, maar voor mij
is het aantrekkelijke van podcasts de stemmen, de
leuke vibe tussen te podcastmakers. En het valt te
vrezen dat dit een groot gemis zal zijn in de AI
podcasts. Maar probeer het zelf, en laat ons iets
weten? Dit is een
van de tools die op AI gebaseerd zijn, waarbij wij
wel vragen stellen. Ja, bij AI tools waar je
vragen kan stellen over een bepaald onderwerp,
krijg je tekst, die je kan lezen. Maar deze tool
beweert een stap verder te gaan, en over dat
onderwerp een heuse podcast te kunnen maken. Nu,
ik weet niet hoe het voor jou zit, maar voor mij
is het aantrekkelijke van podcasts de stemmen, de
leuke vibe tussen te podcastmakers. En het valt te
vrezen dat dit een groot gemis zal zijn in de AI
podcasts. Maar probeer het zelf, en laat ons iets
weten?
[Taal: EN]
https://apps.apple.com/us/app/rome-ai/id6503020264
|
HUMAN OR NOT?
 Een
interessante webapp, waarbij jij zelf kan
uitvinden of je een AI-bot kan onderscheiden van
een echte persoon. Gedurende anderhalve minuut kan
je vragen stellen, en dan moet je het antwoord
geven: bot of echte mens. Wat ons wel stoort is
dat je niet te weten komt waarom je het verkeerd
voor had. En eigenlijk is deze quiz een reclame
voor een tool, Wordtue, die belooft door AI
aangemaakte tekst om te kunnen vormen in teksten
alsof die door echte mensen gebracht zouden zijN. Een
interessante webapp, waarbij jij zelf kan
uitvinden of je een AI-bot kan onderscheiden van
een echte persoon. Gedurende anderhalve minuut kan
je vragen stellen, en dan moet je het antwoord
geven: bot of echte mens. Wat ons wel stoort is
dat je niet te weten komt waarom je het verkeerd
voor had. En eigenlijk is deze quiz een reclame
voor een tool, Wordtue, die belooft door AI
aangemaakte tekst om te kunnen vormen in teksten
alsof die door echte mensen gebracht zouden zijN.
[Taal: EN]
https://app.humanornot.ai/
|
MELODYSCRIBE: MUZIEK LATEN UITSCHRIJVEN
 Op deze
webdienst kan je verschillende muziekformaten
uploaden, zoals een .midi, .mid of zelfs een .pdf
bestand. De too zal die dan omzetten in bladmuziek
met notities. Zo kan je verder werken aan je
muziek en die perfectioneren, zonder dat je je
moet bekommeren over een manuele transcriptie. Op deze
webdienst kan je verschillende muziekformaten
uploaden, zoals een .midi, .mid of zelfs een .pdf
bestand. De too zal die dan omzetten in bladmuziek
met notities. Zo kan je verder werken aan je
muziek en die perfectioneren, zonder dat je je
moet bekommeren over een manuele transcriptie.
[Taal: En]
https://www.melodyscribe.com/
|
TOOLSTASH: WAAR LIGT MIJN GEREEDSCHAP?
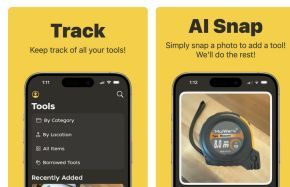 Een ideale
tool voor wie al eens gereedschap uitleent.
Hiermee kan je namelijk opvolgen welk gereedschap
je zelf hebt, en waar je dat gelaten hebt. Maar
ook welke buur dat gerief geleend heeft, maar ook
(als de buren meedoen met de app) welke buur een
tool heeft die jij nodig hebt. Een ideale
tool voor wie al eens gereedschap uitleent.
Hiermee kan je namelijk opvolgen welk gereedschap
je zelf hebt, en waar je dat gelaten hebt. Maar
ook welke buur dat gerief geleend heeft, maar ook
(als de buren meedoen met de app) welke buur een
tool heeft die jij nodig hebt.
[Taal: En]
https://toolstash.com/
|
Bezoek
ook de andere projecten van de
Netties-medewerkers:
Wim
W.: http://www.tenbunderen.be/
- http://www.nieuwsbronnen.com/
Sjeef:
http://www.sjeef.eu/Nederlands/projecten.html
Hilde:
http://hoorspel.wordpress.com

|
W I K I P E D I A
Een selectie van nieuwe en
actuele bijdragen in
de
Nederlandstalige versie van Wikpedia
|
Wikipedia is een project met als doel een complete
encyclopedie op het web te creëren. Iedereen kan
Wikipedia gebruiken om informatie te zoeken of toe te
voegen. U kunt eenvoudig zelf artikels schrijven,
corrigeren of aanvullen. Aanmelden is hiervoor niet
nodig, u kunt door op een van de onderstaande pagina's
op "Pagina bewerken" te klikken meteen aan de slag.
Deze week zijn onder meer nieuwe artikels verschenen
over:
Lange afstandsroute voor fietsers in
Picardisch Wallonië - https://nl.wikipedia.org/wiki/Route_des_Collines
Spoorlijn in Slowakije -
https://nl.wikipedia.org/wiki/Spoorlijn_%C4%8Cerven%C3%A1_Skala_%E2%80%93_Margecany
Gefortificeerde, afsluitbare ruimte
in een gebouw of vaartuig - https://nl.wikipedia.org/wiki/Paniekkamer
Vrije werkomgeving van UBports voor
besturingssystemen die tot de Unixfamilie behoren - https://nl.wikipedia.org/wiki/Lomiri
Reeks grotten gebruikt als rotswoning
in het Pinnacle Point voorgebergte direct ten zuiden van
Mosselbaai in de Zuid-Afrikaanse provincie West-Kaap - https://nl.wikipedia.org/wiki/Pinnacle_Point_Caves
Artistiek kunstwerk in Amsterdam-Zuid
- https://nl.wikipedia.org/wiki/Dagboekfragment_uit_Het_Achterhuis
Nummer van de Amerikaanse
soul-/R&B-groep Rose Royce - https://nl.wikipedia.org/wiki/Wishing_on_a_Star
De opkomst van modern menselijk
gedrag: de pleistocene bezettingsplaatsen van
Zuid-Afrika -
https://nl.wikipedia.org/wiki/De_opkomst_van_modern_menselijk_gedrag:_de_pleistocene_bezettingsplaatsen_van_Zuid-Afrika
Belgisch bankier en muziekmecenas en
-criticus - https://nl.wikipedia.org/wiki/Henry_Le_B%C5%93uf
Daarnaast zijn onder andere de volgende bijdragen
actueel:
Brandstichtingen op Franse spoorwegen
in 2024 -
https://nl.wikipedia.org/wiki/Brandstichtingen_op_Franse_spoorwegen_in_2024
Regeringsformaties in België 2024 - https://nl.wikipedia.org/wiki/Regeringsformaties_in_Belgi%C3%AB_2024
49e vicepresident van de VS en
presidentskandidate - https://nl.wikipedia.org/wiki/Kamala_Harris
Gerelateerd aan de olympische
zomerspelen 2024:
Gymnastiek op
de Olympische Zomerspelen 2024 – Meerkamp individueel
mannen -
https://nl.wikipedia.org/wiki/Gymnastiek_op_de_Olympische_Zomerspelen_2024_%E2%80%93_Meerkamp_individueel_mannen
Triatlon op
de Olympische Zomerspelen 2024 – Vrouwen -
https://nl.wikipedia.org/wiki/Triatlon_op_de_Olympische_Zomerspelen_2024_%E2%80%93_Vrouwen
Verdere bijzonderheden op de Nederlandstalige Wikipedia:
Het portaal van de week gaat over de
film noir - https://nl.wikipedia.org/wiki/Portaal:Film_noir
Uitgelicht artikel: Ruimtelijke
ordening - https://nl.wikipedia.org/wiki/Ruimtelijke_ordening
Enkele etalage-artikelen:
Yosemite
National Park - https://nl.wikipedia.org/wiki/Yosemite_National_Park
Waterbeertjes
of beerdiertjes - https://nl.wikipedia.org/wiki/Beerdiertjes
Habsburgse
monarchie - https://nl.wikipedia.org/wiki/Habsburgse_monarchie
De vorige bijdragen van Wikipedia aan NeTTieS zijn hier
te vinden: http://nl.wikipedia.org/wiki/Wikipedia:Wekelijkse_bijdrage_in_NeTTieS
| |
Bij de collega's
|
*** ALGEMEEN DAGBLAD
http://www.ad.nl/multimedia

Deze draadloze speaker komt als beste uit de test
én is de beste koop
Wat is de beste kleine, draadloze speaker voor
onderweg? En welke heeft de beste
prijs-kwaliteitverhouding? De Consumentenbond geeft
antwoord.
https://www.ad.nl/tech/deze-draadloze-speaker-komt-als-beste-uit-de-test-en-is-de-beste-koop~a6105f0e/
*** COMPUTERTAAL
http://www.computertaal.info

E-mails blokkeren
in Gmail
Gmail is een handige e-mail client: gratis, met
redelijk wat opslagruimte en een degelijke spamfilter.
Dat betekent echter niet dat je altijd mail krijgt die
je wil ontvangen, en soms wil je die gewoon blokkeren,
zeker als je mijn probleem hebt: dat je nog meer dan
16.000 mails achter loopt…
https://computertaal.info/2024/08/02/e-mails-blokkeren-in-gmail/
*** TWEAKERS NET
http://www.tweakers.net

'Amerikaanse overheid doet onderzoek
naar monopolie Nvidia op AI-markt'
Het Amerikaanse ministerie van Justitie is twee
verschillende onderzoeken gestart naar Nvidia, schrijven
Politico en The Information op basis van interne
bronnen. Het techbedrijf zou een mogelijk monopolie
hebben op de AI-markt
https://tweakers.net/nieuws/225064/amerikaanse-overheid-doet-onderzoek-naar-monopolie-nvidia-op-ai-markt.html
*** DATANEWS
http://www.datanews.be

België dreigt
chipfabrikant BelGaN te verliezen, Agoria pleit voor
snelle doorstart
Chipproducent BelGaN in Oudenaarde vroeg eerder deze
week het faillissement aan, waardoor zo’n 440
medewerkers hun baan dreigen te verliezen. Jolyce
Demely, directeur van technologiefederatie Agoria
Vlaanderen, betreurt de situatie en roept de Vlaamse
regering in lopende zaken op om alle verschillende
mogelijkheden voor ondersteuning te onderzoeken.
https://datanews.knack.be/nieuws/bedrijven/herstructurering/belgie-dreigt-chipfabrikant-belgan-te-verliezen-agoria-pleit-voor-snelle-doorstart/
|
|
Van alles halen, (bijna)
niets betalen...
|
ADVANCED RENAMER 4.0
 Deze tool
is eigenlijk een veteraan als het erop aankomt om
bestanden te hernoemen op je Windows of Mac
computer. Van deze tool is er nu een nieuwe versie
uit. Die bevat vele nieuwigheden, waaronder native
extractie van metadata, om die in de
hernoemoperatie te gebruiken snellere werking, en
veel meer. Deze tool
is eigenlijk een veteraan als het erop aankomt om
bestanden te hernoemen op je Windows of Mac
computer. Van deze tool is er nu een nieuwe versie
uit. Die bevat vele nieuwigheden, waaronder native
extractie van metadata, om die in de
hernoemoperatie te gebruiken snellere werking, en
veel meer.
[20$]
https://www.advancedrenamer.com/download
https://www.advancedrenamer.com/whatsnew_v4
|
MUSIC DATASTATS
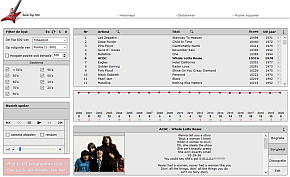 Music
Datastats is een gratis programma dat een
overzicht biedt van talrijke Nederlandse,
Belgische en Duitse muzikale hitlijsten. Je kunt
deze database heel makkelijk koppelen aan je eigen
muziekbestanden, waarna je die in het
programma kunt beluisteren. Daarbij krijg je
dan ook de songteksten te zien en een korte
bio van de artiest of groep. De maker was fan van
de Nederlandse Top 2000 en maakte daarvan zijn
eerste overzicht. Dat sloeg aan bij vrienden en
vervolgens is bij steeds meer lijsten aan het
programma gaan toevoegen. En hij voegt er nog
steeds lijsten aan toe. Bij het opstarten wordt de
database dan ook automatisch ververst. Music
Datastats is een gratis programma dat een
overzicht biedt van talrijke Nederlandse,
Belgische en Duitse muzikale hitlijsten. Je kunt
deze database heel makkelijk koppelen aan je eigen
muziekbestanden, waarna je die in het
programma kunt beluisteren. Daarbij krijg je
dan ook de songteksten te zien en een korte
bio van de artiest of groep. De maker was fan van
de Nederlandse Top 2000 en maakte daarvan zijn
eerste overzicht. Dat sloeg aan bij vrienden en
vervolgens is bij steeds meer lijsten aan het
programma gaan toevoegen. En hij voegt er nog
steeds lijsten aan toe. Bij het opstarten wordt de
database dan ook automatisch ververst.
Op dit moment staan er 15 Nederlandse, 7 Belgische
en 1 Duitse hitlijst in.
[Henk Langerak]
Gratis downloaden op:
http://datastats.nl/
|
LAY-OUT: APP VOOR META QUEST 3
 Heb je een
Quest 3 headset van Meta? Dan is dit een handige
tool. Met Layout kan je namelijk in mixed reality
afmetingen noteren. Je richt de headset op
voorwerpen zoals meubels, en je kan de hoogte,
lengte en diepte ervan meten. Nog een handige
toepassing is dat je kan bekijken hoe nieuwe
meubels in je interieur zouden staan. Heb je een
Quest 3 headset van Meta? Dan is dit een handige
tool. Met Layout kan je namelijk in mixed reality
afmetingen noteren. Je richt de headset op
voorwerpen zoals meubels, en je kan de hoogte,
lengte en diepte ervan meten. Nog een handige
toepassing is dat je kan bekijken hoe nieuwe
meubels in je interieur zouden staan.
Een uitvoerige bespreking bij The Verge.
https://www.theverge.com/2024/7/30/24209438/meta-quest-layout-app-measurements-mixed-reality
https://www.meta.com/nl-nl/experiences/9298251876913852/
|
ALOHA: ALTERNATIEVE WEBBROWSER
 Er zijn wel meerdere
browsers die beloven een alternatief te zijn voor
de bekendste browsers (Firefox, Safari,
Edge). Aloha belooft iets wat browsers zoals
DuckDuckGo verzekeren, Brave, Vivaldi en
Librewolf. De browser is enkel voor iOS
verkrijgbaar en biedt verschillende voordelen,
zoals inloggen met passcode en Face/Touch ID, een
rapport dat je vertelt hoeveel advertenties,
trackers en pop-ups je al geblokkeerd hebt, en
meer. Er zijn wel meerdere
browsers die beloven een alternatief te zijn voor
de bekendste browsers (Firefox, Safari,
Edge). Aloha belooft iets wat browsers zoals
DuckDuckGo verzekeren, Brave, Vivaldi en
Librewolf. De browser is enkel voor iOS
verkrijgbaar en biedt verschillende voordelen,
zoals inloggen met passcode en Face/Touch ID, een
rapport dat je vertelt hoeveel advertenties,
trackers en pop-ups je al geblokkeerd hebt, en
meer.
https://alohabrowser.com/
|
SOUNDFORGE: MUZIEKSTUDIO
 Met deze
tool kan je muziek opnemen, bewerken, herstellen
en mengen, met echt wel de nieuwste technologieën.
Je kan zo podcasts opnemen in uitzonderlijk hoge
kwaliteit, je projecten bewerken met professionele
effecten, vinyl platen en cassettes omzetten naar
digitale bestanden, soundtracks maken voor video's
en veel meer. Met deze
tool kan je muziek opnemen, bewerken, herstellen
en mengen, met echt wel de nieuwste technologieën.
Je kan zo podcasts opnemen in uitzonderlijk hoge
kwaliteit, je projecten bewerken met professionele
effecten, vinyl platen en cassettes omzetten naar
digitale bestanden, soundtracks maken voor video's
en veel meer.
[Windows - $19,99]
https://apps.microsoft.com/detail/9pgsq8hzlwr5?hl=nl-nl&gl=us
|
(Deze tips voor share- en freeware zijn afkomstig van
verschillende sites, o.a. Freewareweb, Lockergnome,
ZDNet, PCWorld, en andere.
NeTTies e-zine
p/a Hilde Van Gool
Bossestraat 32
2220 Heist op den Berg
Coordinator:
Hilde Van Gool
Tel 0475/53.41.20 -
015/25.28.71
|
- "NeTTies" is
gratis te verkrijgen door te vragen om aan
onze abonneelijst te worden toegevoegd.
Dit kan online op onze site, of per
e-mail.
- Te allen
tijde kunt u het abonnement ook weer
stopzetten, eveneens via de site of per
e-mail.
- Uw adres
wordt niet aan derden doorgegeven en wordt
niet gebruikt voor commerciële doeleinden.
- "NeTTies" is
onafhankelijk en wordt geheel op
vrijwillige basis gemaakt.
- "NeTTies is
niet verantwoordelijk voor eventuele
schade veroorzaakt door het gebruik van
software waarover wij publiceren.
- Teksten mogen
worden overgenomen, maar uitsluitend met
bronvermelding.
- "NeTTies" mag
wel in z'n geheel worden doorgestuurd naar
derden ter kennismaking.
- "NeTTIes"
moedigt lezers aan een link te zetten op
hun webpagina. De aanwezigheid van een
verwijzing naar ons e-zine betekent echter
niet dat wij het eens zijn met de
redactionele inhoud op die site.
- De
advertenties die op "NeTTies" geplaatst
worden door derden vallen buiten de
verantwoordelijkheid van de redactie en
geven geenszins de mening van de redactie
weer. Bij deze teksten wordt
duidelijk aangegeven dat het om een
advertentie gaat.
Voor alle
duidelijkheid even op rij onze regels
voor de bescherming van uw privacy:
- Uw adres
wordt nooit aan derden doorgegeven.
- Uw adres
wordt ook niet voor marketingdoeleinden
gebruikt.
- NeTTies zal
u nooit reclameboodschappen van derden
doorsturen in een aparte mail.
- In onze
nieuwsbrief zal wel van tijd tot tijd
een advertentie opgenomen worden, in het
kader van sponsoring.
Deze tekst
werd voor het laatst aangepast op 14
januari 2004
Wij danken de vele
mensen die nu of in het verleden hebben
meegewerkt aan dit e-zine:
Miranda Swier, Benny Raemaekers, Geert
Demuynck, Kurt Fierens, Peter Stuart,
Gerard Schaefers (Sjeef), Boeloeboeloe
(LVO), Manu Drieghe, Marijke Pante,
Marianne Steijlen, Reinhilde Remaut,
Ludo Cattoor, Evert Poppen, Philip
Lafeber, Julien Van den Borre, Johan
Junior, Kurt op de Beeck, Koen van
Poucke, Rogier P. Bakx, Jurgen Veys,
Nick Toretto, Krekkie, Dave Lahousse,
Filip Overmeire (Filover), Jeffrey
Drooghenbroodt, Human0id, Danny Zeegers,
Wim Wilyn, Dave Lahousse, Ben Depré,
Eddy Horemans, Henk Langerak, Arnold
Top, Jan Van Reeth, Fruggo, Paul
Liekens.
In het bijzonder danken wij Gerard
Schaefer voor zijn tips en de spreuk van
de week.
Webhosting,
cms, verzending: Webdynamics
Eindredactie:
Hilde Van Gool, en vanuit de eeuwigheid:
Niek Harmans
Logistiek: Paul
Liekens
Secretaresse: Carol Fenijn
"NeTTies" is
een oorspronkelijk concept van Jean-Luc
Bostyn
De eindredactie
van NeTTies ligt in handen van Hilde
Van Gool,
freelance
publiciste.
U
ontvangt deze mail omdat u zich
in het verleden aangemeld hebt
als abonnee op deze nieuwsbrief.
Wenst u uw
abonnement te wijzigen of te
annuleren? Daarvoor kan u
terecht op onze website: https://www.netties.be/v20/abonnement.php
|
|
AFSLUITER
VAN DE WEEK
Als iemand op mijn begrafenis
moppert,
spreek ik nooit meer met hem.
-Stanley Laurel-
[ de helft
van het komisch duo “De dikke en de Dunne”]]
|

